Blogs
Weekly blogs starting next week
Coming soonSoftware Engineer (Agentic AI, System Design & Cloud Architecture)
I build AI systems that are useful beyond the demo: agentic workflows, retrieval systems, durable background jobs, and cloud architectures that can survive real constraints.
Designing tool-using AI workflows with retrieval, structured outputs, orchestration, and feedback loops that stay grounded in product needs.
Building systems with queues, durable state, observability, storage boundaries, and deployment paths that make AI applications reliable.
Turning research ideas into working products through evaluation, graceful degradation, and careful engineering trade-offs.
Agentic AI, retrieval, cloud architecture, and learning systems presented as focused case studies.
Turns YouTube playlists into durable courses with notes, search, quizzes, spaced repetition, exports, diagrams, and an MCP interface.
Multi-user document Q&A with async OCR, hybrid retrieval, user isolation, object storage, and AWS deployment.
Personal AI intelligence reader that ingests technical sources, enriches them, ranks them, and serves a mobile research feed.
Local-first study notes app that converts PDFs and slides into structured notes while preserving diagrams in context.
VS Code extension that observes coding behavior and returns reflective feedback about process, debugging, and blind spots.
Live Double DQN Pong trainer with reward shaping controls, real-time analytics, step mode, and survival battle mode.
No projects match the selected filters.
Project case study
YouTube has excellent courses, but playlists are passive, hard to search, difficult to review, and fragile when AI processing hits rate limits. CourseFlow turns a playlist into a durable learning system with transcripts, notes, quizzes, search, review cards, exports, and optional diagrams.
The project demonstrates production-oriented AI architecture: asynchronous queues, resumable work, quota-aware scheduling, private object storage, vector search, state machines, and cloud deployment. It also fits the real learner workflow: watch, search, quiz, review, and export without restarting from scratch after failures.
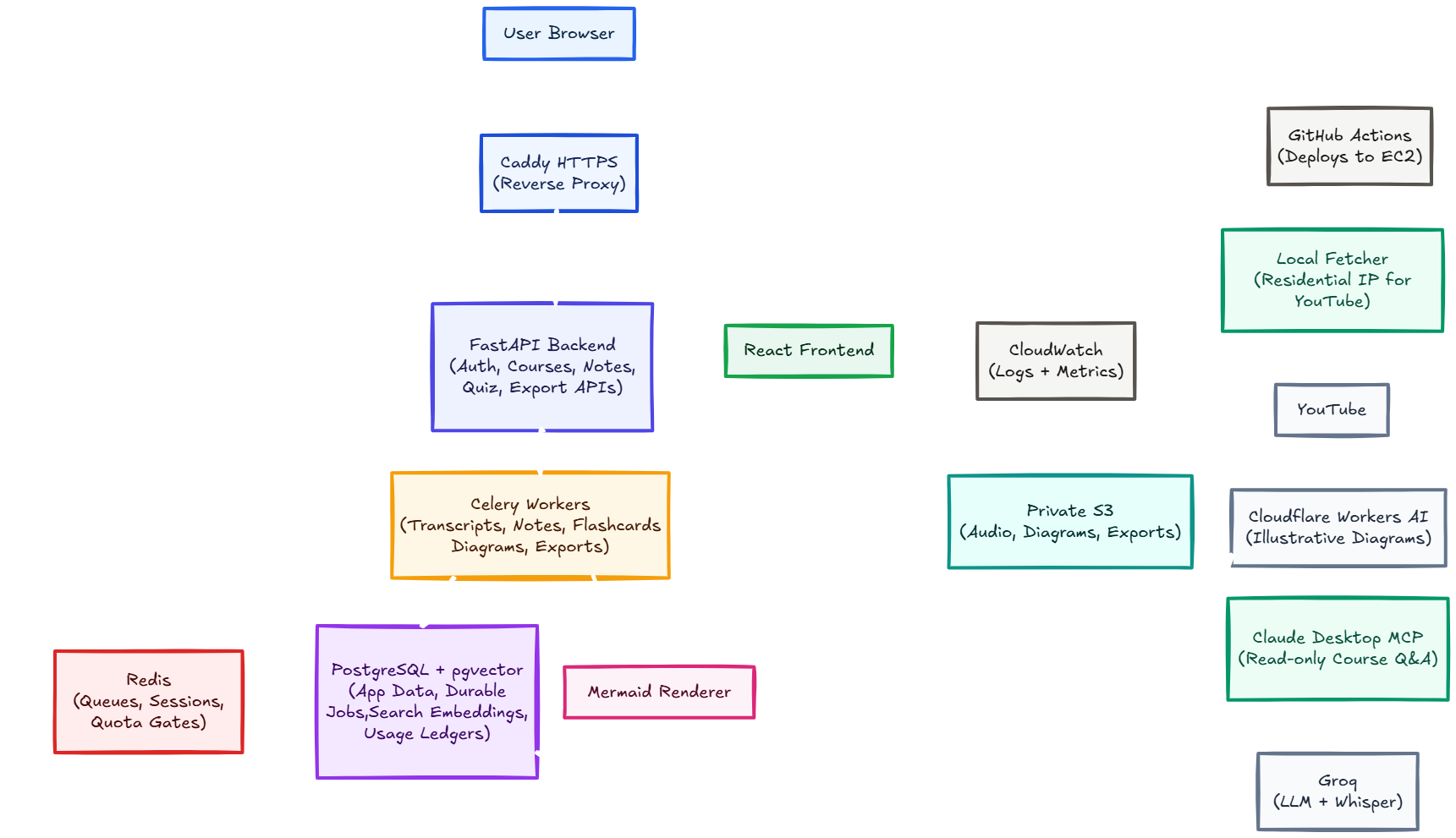
Ingests playlists or videos, tracks every video state, retries failures, and checkpoints transcript and note chunks.
Generates structured notes, semantic search, adaptive LangGraph quizzes, SM-2 spaced repetition cards, and exam planning.
Supports Mermaid and optional illustrative diagrams, then exports lessons or complete courses as Markdown, PDF, or Anki decks.
Exposes user-scoped course listing, search, and grounded Q&A through a local read-only MCP server.
Transcription, notes, embeddings, PDFs, and diagrams run through Celery so HTTP requests stay responsive.
Redis handles fast counters and active state; PostgreSQL stores durable usage events and recoverable processing state.
A local fetcher handles YouTube calls that are sensitive to datacenter blocking, while AWS owns durable state and user-facing services.
Groq response headers drive backpressure and retry timing, reducing repeated failures under rate limits.
CourseFlow is the strongest expression of my current interests: agentic workflows, cloud architecture, durable distributed jobs, retrieval, and real product-grade system design around AI constraints.
Project case study
Users need a private way to upload documents, organize them, and ask grounded questions across PDFs and images. Docflow solves this with multi-user authentication, async processing, OCR, hybrid retrieval, chat history, and source-grounded answers.
Document Q&A is only useful when retrieval is accurate and user isolation is strict. Docflow combines parent-child chunking, vector search, BM25, and Reciprocal Rank Fusion while keeping every file, chat, object key, and vector scoped to the authenticated user.
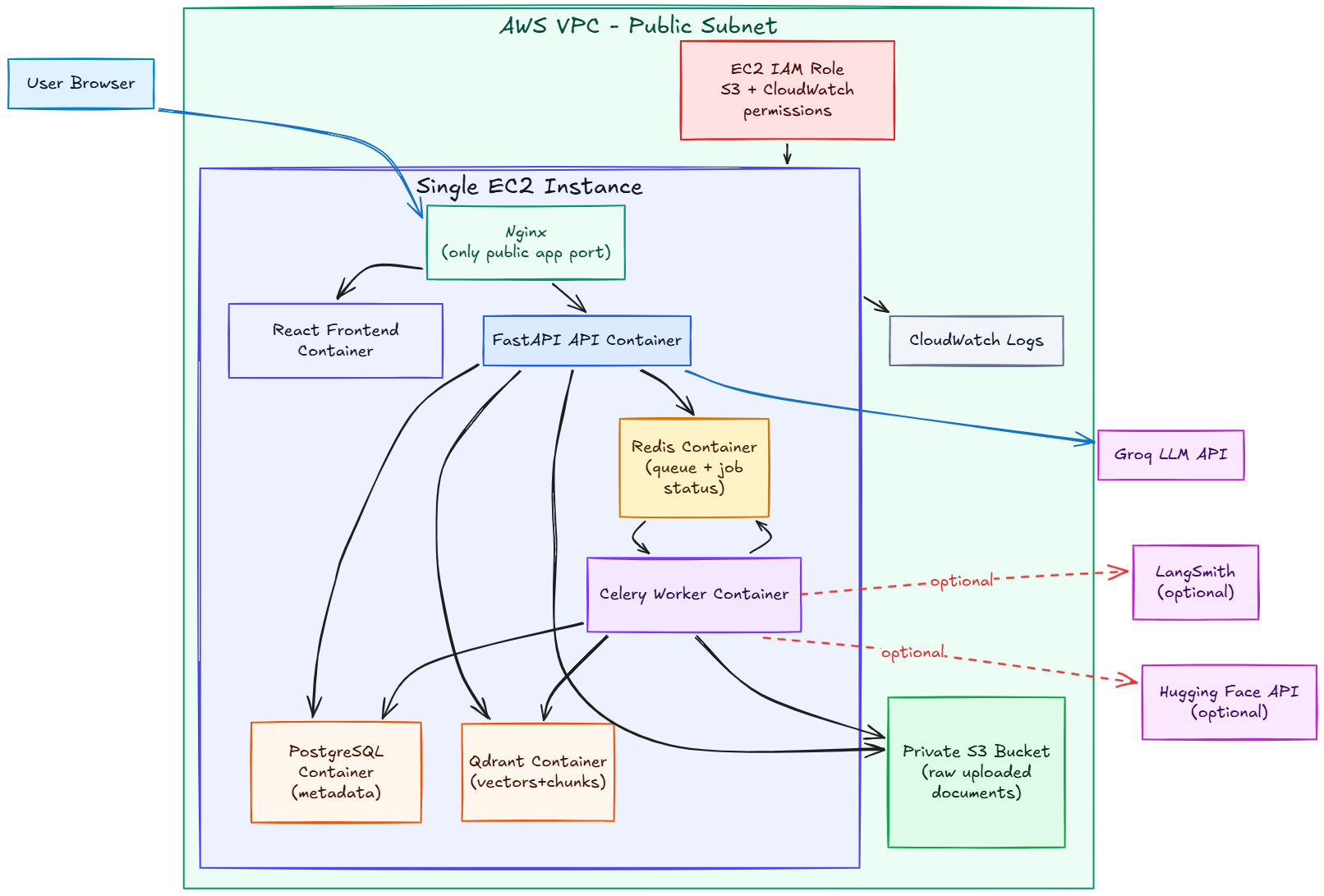
Accepts PDFs and images, stores raw files, queues work, extracts text, performs OCR for scanned PDFs, and tracks processing status.
Combines Qdrant vector search with BM25 keyword search and Reciprocal Rank Fusion for robust document lookup.
Supports separate files, chats, messages, and search results for every user with bearer-token sessions.
Runs on EC2 with Nginx, containers, private S3 storage, PostgreSQL, Redis, Qdrant, CloudWatch logs, and IAM role credentials.
Celery and Redis keep upload requests fast while the worker handles extraction, OCR, chunking, embeddings, and vector writes.
Small child chunks improve retrieval precision; larger parent chunks give the LLM enough context to answer coherently.
Database rows, object keys, and Qdrant payloads all carry ownership metadata to prevent cross-user leakage.
The prompt instructs the model to say when evidence is missing instead of inventing unsupported document facts.
Docflow shows practical RAG beyond a demo: background jobs, hybrid retrieval, cloud storage, tenant isolation, operational logging, and grounded generation.
Project case study
Engineers and researchers follow too many sources: RSS feeds, GitHub, arXiv, newsletters, and saved articles. Pulse collects this information, normalizes it, enriches it with AI, and serves a personalized mobile feed.
A useful technical reader needs more than summaries. It needs ingestion isolation, deduplication, ranking, semantic search, learning modes, digests, trends, and a deployment path that can run cheaply for a single owner.
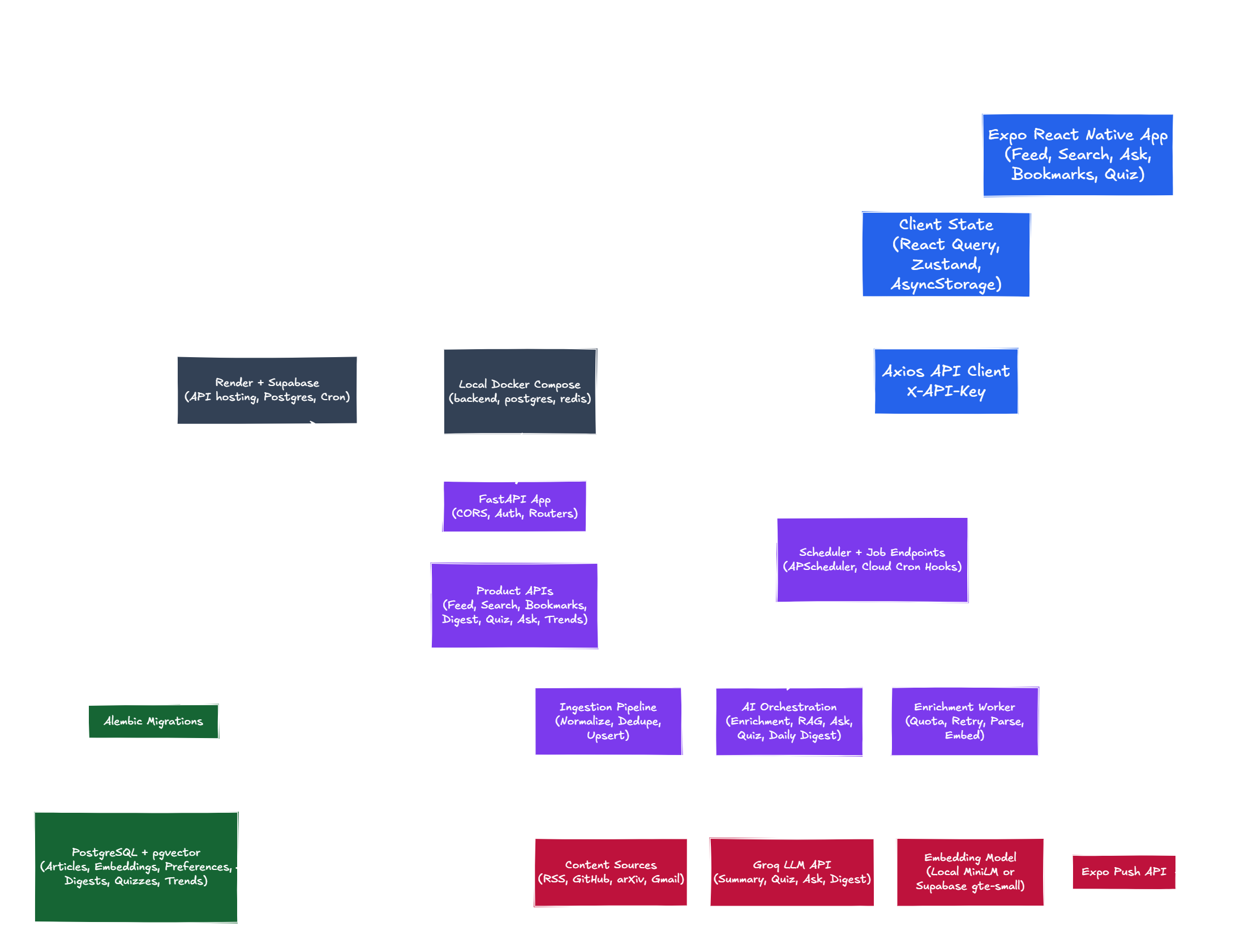
Collects AI and software content from RSS, GitHub, arXiv, and Gmail newsletters with normalization and deduplication.
Uses structured Groq calls for summaries, categories, entities, and scoring.
Ranks content using reading, bookmarking, and hiding behavior, with offline cache and network states in the Expo app.
Includes semantic and hybrid search, LangGraph Socratic quizzes, corpus-grounded Ask mode, digests, and trends.
Combines relational content metadata with pgvector semantic retrieval and full-text search.
Ingestion normalizes and deduplicates sources independently so one failing source does not poison the entire feed.
Uses a static API key as a lightweight access gate, suitable for personal deployment but explicitly not multi-user auth.
Supports local Docker and a zero-cost Render + Supabase route for running the system as a personal tool.
Pulse is a personal intelligence system: ingestion, enrichment, retrieval, ranking, and mobile UX tied together into a daily engineering workflow.
Project case study
Lecture PDFs and slides often contain important diagrams that disappear when converted into plain text prompts. Smart Notes Generator creates structured notes while preserving extracted figures in the right context.
Students need trustworthy notes from private course material without sending images to an external model. This project uses a local-first workflow where files and images stay on the machine while text prompts preserve diagram placeholders.
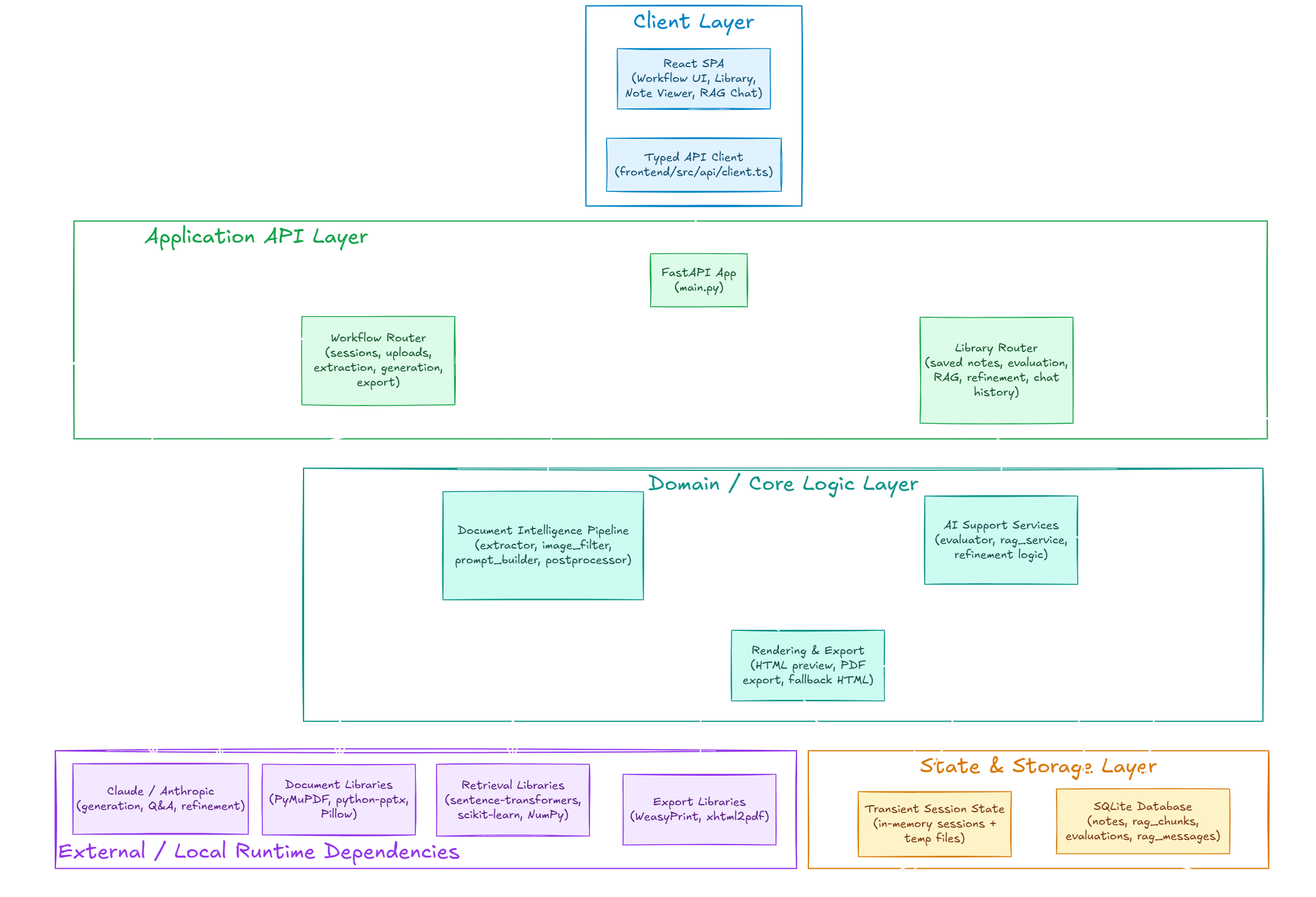
Processes PDFs and PowerPoints, extracts raster/vector figures, filters low-quality images, deduplicates repeated assets, and preserves meaningful diagrams.
Sends lightweight placeholders such as IMG tokens to Claude, then restores the original local images after generation.
Scores notes for coverage, structure, density, length, and faithfulness, then supports grounded Q&A over saved notes.
Allows targeted edits on specific sections while preserving diagrams and minimizing prompt size.
Source files and extracted images remain local; the model receives text plus placeholders instead of image payloads.
Temporary generation state lives in memory and OS temp files, while saved notes, evaluations, chunks, and chats live in SQLite.
Semantic embeddings are used when available, with TF-IDF and Jaccard fallbacks for dependency-light environments.
PDF export tries WeasyPrint, falls back to xhtml2pdf, and finally returns browser-printable HTML.
Smart Notes Generator shows careful AI product design around privacy, cost, graceful degradation, evaluation, and diagram-preserving postprocessing.
Project case study
Most coding assistants optimize for the final answer. AI Learning Coach focuses on how the learner thinks while solving DSA and competitive programming problems.
Learners often repeat hidden process mistakes: skipping planning, rewriting the same region, mishandling boundaries, or abandoning approaches after pauses. The extension turns the IDE into an event-driven learning observatory and gives reflective feedback without leaking solutions.
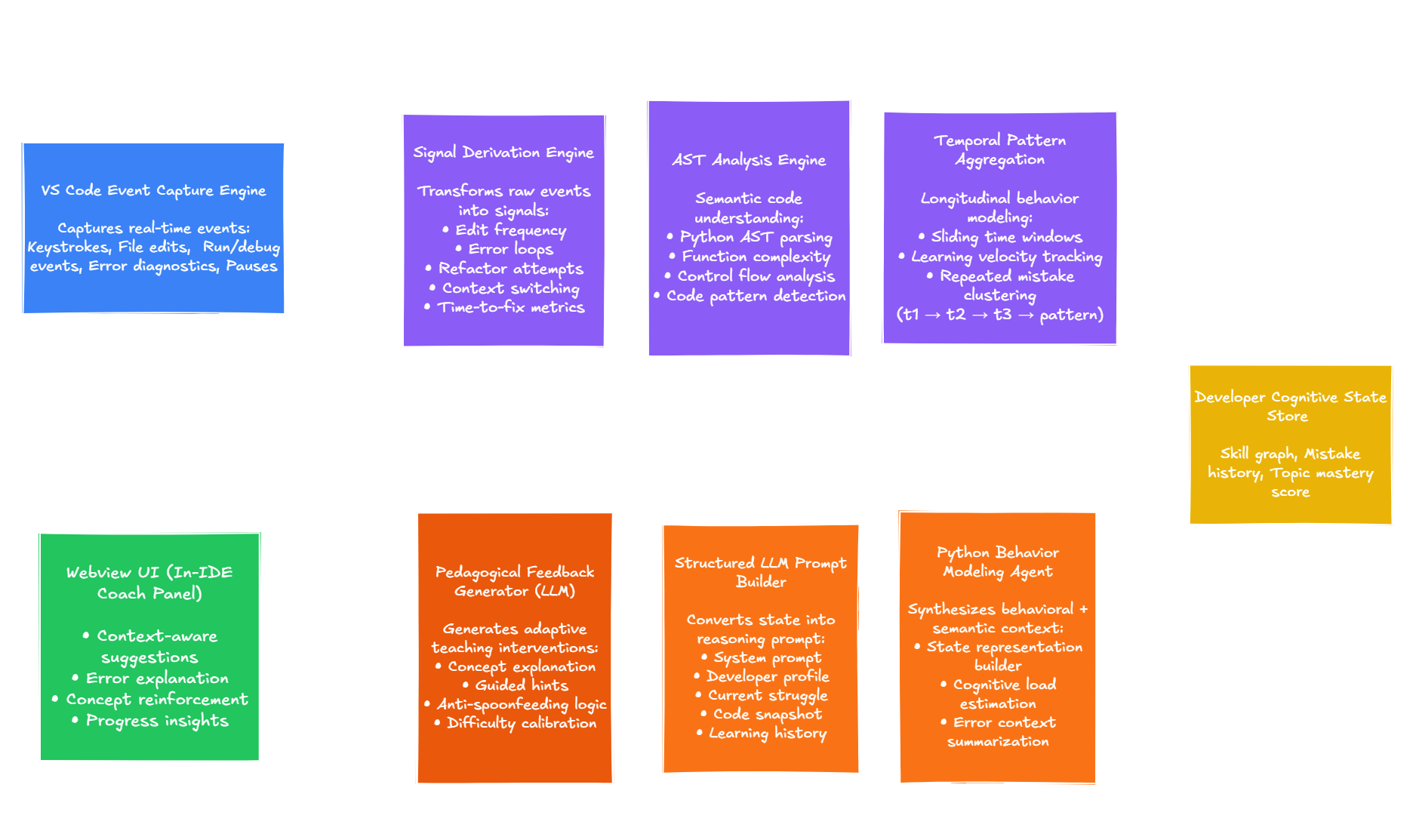
Captures pasted LeetCode, Codeforces, or plain-text statements and extracts title, difficulty, constraints, examples, tags, and expected complexity when available.
Records edits, saves, diagnostics, cursor movement, idle time, undo/redo-like behavior, and AST snapshots.
Returns structured observations, issues, process feedback, learning suggestions, and reflection questions in a VS Code webview.
Raw editor events are noisy, so the extension derives compact metrics such as edit churn, planning time ratio, boundary error density, and abandoned attempts.
The extension talks to a Python agent over line-delimited JSON, separating editor concerns from feedback generation.
Pydantic schemas keep LLM feedback predictable and prevent the webview from receiving unstructured assistant output.
The prompt emphasizes process feedback and avoids direct code fixes or full solutions.
AI Learning Coach is an agentic developer-tool project focused on behavior modeling, structured context, and useful feedback rather than shortcut generation.
Project case study
RL training loops are often opaque. This project creates a visual Pong environment where a Double DQN agent trains online while exposing reward, loss, Q-values, actions, and state dynamics.
Reinforcement learning becomes easier to understand when reward shaping, exploration, target networks, and policy behavior can be inspected live. The trainer turns a classic control problem into an interactive laboratory.
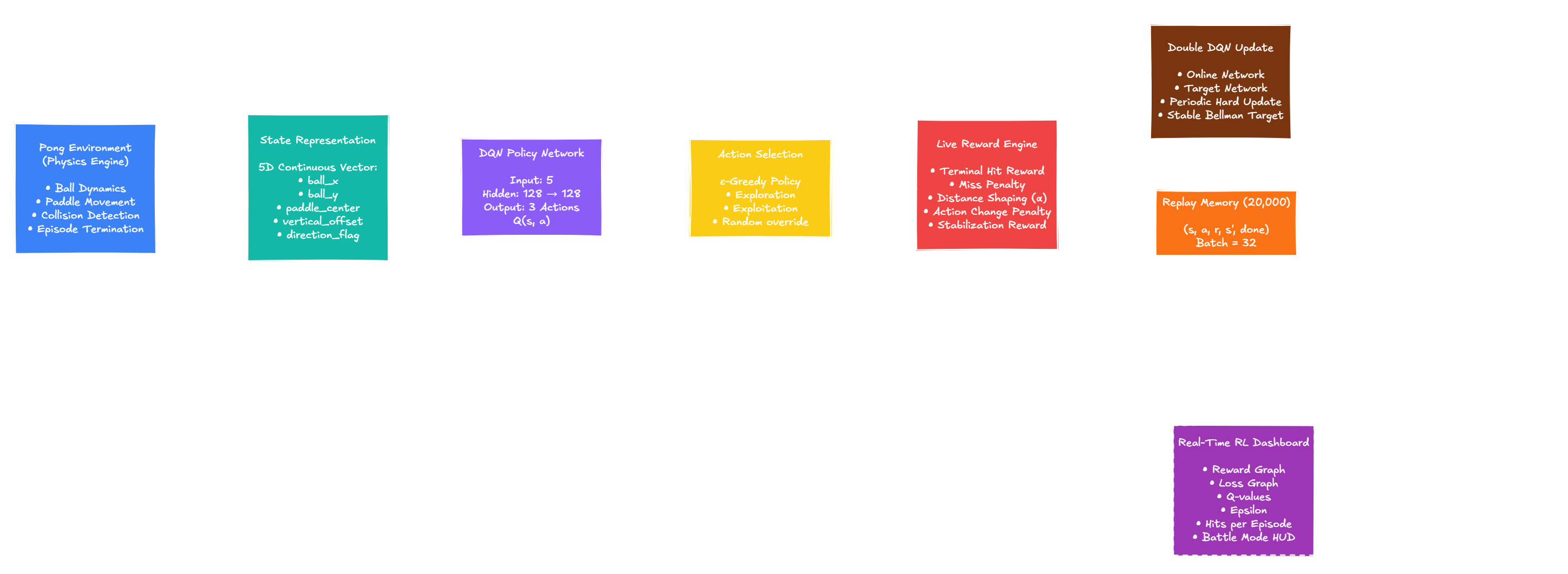
Lets users tune terminal rewards, miss penalties, alignment rewards, shaping alpha, and action-change penalties at runtime.
Manual stepping mode shows recent reward, loss, state information, and training behavior frame by frame.
Runs a greedy survival challenge with escalating difficulty and a persistent CSV leaderboard.
Saves model weights, target network, optimizer state, episode counters, reward/loss history, and hit statistics.
Distance-to-intercept shaping provides feedback while the ball is still moving, reducing the sparseness of Pong rewards.
Uses a target network and Double DQN targets for more stable online learning.
Supports perfect, heuristic, and human opponents to test different training and evaluation conditions.
Graphs and diagnostics are rendered directly into the game loop so the learning process stays visible.
The RL trainer reflects my interest in making complex learning systems inspectable, tunable, and grounded in actual behavior rather than hidden training logs.
Notes on agentic AI, system design, cloud architecture, and lessons from building real AI systems.
Weekly blogs starting next week
Coming soonAcademic contributions through publications
The generation of radiology reports forms a very important aspect of medical imaging, which furnishes physicians with timely and accurate diagnostic information. However, interpreting medical images and compiling their findings remains cumbersome for radiologists. To address this challenge, we propose an automatic report generation system based on the BLIP (Bootstrapping Language-Image Pre-training) model. By fine-tuning a pre-trained BLIP image captioning framework using paired chest X-ray images and their corresponding diagnostic reports, the model learns to describe visual findings in clear and clinically relevant text. Experimental results show that our model achieves strong performance with BLEU, METEOR, ROUGE, and RadGraph-F1 scores of 0.5859, 0.4021, 0.6780, and 0.6424 respectively, demonstrating its ability to generate meaningful and clinically grounded descriptions.
My Contribution: Lead researcher, conducted experiments, wrote parts of the manuscript.
Explored sentiment classification in Tamil-English and Tulu-English code-mixed datasets using both machine learning (ML) and deep learning (DL) approaches. DL models, while theoretically capable of capturing richer contextual and semantic relationships, underperform with limited data availability. ML models are better suited for sentiment analysis of code-mixed texts, particularly in low-resource settings, as they effectively leverage n-gram-based features without requiring extensive labeled data.
My Contribution: Conducted experiments for DL, wrote manuscript.
Language Identification (LI) is a major component for various applications such as Sentiment Analysis, Machine Translation, Information Retrieval, and Natural Language Processing. In multilingual countries like India, especially among the younger generation, social media often contains code-mixed texts where local languages are combined with English. We analyze the performances of 5 models using 2 different vectorizers for the Word-Level Language Identification of Dravidian Languages.
My Contribution: Lead researcher, conducted experiments, wrote manuscript.
I'm a Software Engineer focused on agentic AI, system design, and cloud-native AI applications. My background combines computer science fundamentals from SSN College of Engineering with hands-on experience building retrieval systems, learning platforms, backend workflows, and deployed cloud architectures.
My work is shaped by one recurring question: how do we make AI systems reliable when they move from a notebook to a real product? I care about queues, state, rate limits, isolation, observability, retrieval quality, and the engineering decisions that make intelligent systems maintainable.
Currently, I'm focused on agentic workflows, RAG architectures, MCP integrations, asynchronous processing, PostgreSQL/pgvector systems, and cloud deployments on AWS and adjacent platforms.
I'm seeking opportunities in AI engineering and backend/platform engineering where I can build systems that combine strong AI capability with production-grade architecture.
When I'm not coding or reading papers, I enjoy playing chess, solving rubik's cube, and competitive programming problems.
Download or view my complete professional resume
Last updated: June 2026
Let's connect and discuss opportunities
I'm open to discussing AI engineering, backend/platform roles, cloud architecture work, and research collaborations around agentic systems.
Available for remote opportunities worldwide and open to relocation for the right role.
